![]()
[May 14, 2026] Databricks-Generative-AI-Engineer-Associate Exam Dumps PDF Updated Dump from ValidVCE Guaranteed Success
Pass Your Databricks Exam with Databricks-Generative-AI-Engineer-Associate Exam Dumps
NEW QUESTION # 25
When developing an LLM application, it's crucial to ensure that the data used for training the model complies with licensing requirements to avoid legal risks.
Which action is NOT appropriate to avoid legal risks?
- A. Only use data explicitly labeled with an open license and ensure the license terms are followed.
- B. Reach out to the data curators directly after you have started using the trained model to let them know.
- C. Reach out to the data curators directly before you have started using the trained model to let them know.
- D. Use any available data you personally created which is completely original and you can decide what license to use.
Answer: B
Explanation:
* Problem Context: When using data to train a model, it's essential to ensure compliance with licensing to avoid legal risks. Legal issues can arise from using data without permission, especially when it comes from third-party sources.
* Explanation of Options:
* Option A: Reaching out to data curatorsbeforeusing the data is an appropriate action. This allows you to ensure you have permission or understand the licensing terms before starting to use the data in your model.
* Option B: Usingoriginal datathat you personally created is always a safe option. Since you have full ownership over the data, there are no legal risks, as you control the licensing.
* Option C: Using data that is explicitly labeled with an open license and adhering to the license terms is a correct and recommended approach. This ensures compliance with legal requirements.
* Option D: Reaching out to the data curatorsafteryou have already started using the trained model isnot appropriate. If you've already used the data without understanding its licensing terms, you may have already violated the terms of use, which could lead to legal complications. It's essential to clarify the licensing termsbeforeusing the data, not after.
Thus,Option Dis not appropriate because it could expose you to legal risks by using the data without first obtaining the proper licensing permissions.
NEW QUESTION # 26
A Generative AI Engineer at a legal firm is designing a RAG system to analyze historical legal cases. The system needs to process millions of court opinions and legal documents, already organized by time and topic, to track how interpretations of specific laws have evolved over time. All of these documents are in plain-text. The engineer needs to choose a chunking method that would most effectively preserve continuity and the temporal nature of the cases. Which method do they choose?
- A. Implement sentence level embeddings with each chunk tagged with the time to enable metadata filtering.
- B. Implement paragraph level embeddings with each chunk.
- C. Implement a hierarchical tree structure, like RAPTOR, to group similar legal concepts.
- D. Implement windowed summarization with overlapping chunks.
Answer: D
Explanation:
In the context of legal document analysis where the "evolution of interpretation" is the primary goal, preserving narrative continuity is paramount. Windowed summarization with overlapping chunks is the most effective method for this use case. Overlapping (e.g., 10-15% of the chunk size) ensures that sentences or concepts split at the boundary of one chunk are preserved in the next, preventing the loss of critical context that often occurs in legal jargon. Furthermore, windowed summarization allows the system to condense long-form court opinions into manageable parts while maintaining the chronological "thread" of the argument. While sentence-level embeddings with metadata (D) are useful for filtering, they often lack the sufficient context required to understand the nuances of a legal ruling. A windowed approach provides the LLM with enough surrounding text to understand the "why" behind a legal evolution, rather than just the "when."
NEW QUESTION # 27
A Generative Al Engineer is responsible for developing a chatbot to enable their company's internal HelpDesk Call Center team to more quickly find related tickets and provide resolution. While creating the GenAI application work breakdown tasks for this project, they realize they need to start planning which data sources (either Unity Catalog volume or Delta table) they could choose for this application. They have collected several candidate data sources for consideration:
call_rep_history: a Delta table with primary keys representative_id, call_id. This table is maintained to calculate representatives' call resolution from fields call_duration and call start_time.
transcript Volume: a Unity Catalog Volume of all recordings as a *.wav files, but also a text transcript as *.txt files.
call_cust_history: a Delta table with primary keys customer_id, cal1_id. This table is maintained to calculate how much internal customers use the HelpDesk to make sure that the charge back model is consistent with actual service use.
call_detail: a Delta table that includes a snapshot of all call details updated hourly. It includes root_cause and resolution fields, but those fields may be empty for calls that are still active.
maintenance_schedule - a Delta table that includes a listing of both HelpDesk application outages as well as planned upcoming maintenance downtimes.
They need sources that could add context to best identify ticket root cause and resolution.
Which TWO sources do that? (Choose two.)
- A. maintenance_schedule
- B. call_cust_history
- C. transcript Volume
- D. call_rep_history
- E. call_detail
Answer: C,E
Explanation:
In the context of developing a chatbot for a company's internal HelpDesk Call Center, the key is to select data sources that provide the most contextual and detailed information about the issues being addressed. This includes identifying the root cause and suggesting resolutions. The two most appropriate sources from the list are:
* Call Detail (Option D):
* Contents: This Delta table includes a snapshot of all call details updated hourly, featuring essential fields like root_cause and resolution.
* Relevance: The inclusion of root_cause and resolution fields makes this source particularly valuable, as it directly contains the information necessary to understand and resolve the issues discussed in the calls. Even if some records are incomplete, the data provided is crucial for a chatbot aimed at speeding up resolution identification.
* Transcript Volume (Option E):
* Contents: This Unity Catalog Volume contains recordings in .wav format and text transcripts in .txt files.
* Relevance: The text transcripts of call recordings can provide in-depth context that the chatbot can analyze to understand the nuances of each issue. The chatbot can use natural language processing techniques to extract themes, identify problems, and suggest resolutions based on previous similar interactions documented in the transcripts.
Why Other Options Are Less Suitable:
* A (Call Cust History): While it provides insights into customer interactions with the HelpDesk, it focuses more on the usage metrics rather than the content of the calls or the issues discussed.
* B (Maintenance Schedule): This data is useful for understanding when services may not be available but does not contribute directly to resolving user issues or identifying root causes.
* C (Call Rep History): Though it offers data on call durations and start times, which could help in assessing performance, it lacks direct information on the issues being resolved.
Therefore, Call Detail and Transcript Volume are the most relevant data sources for a chatbot designed to assist with identifying and resolving issues in a HelpDesk Call Center setting, as they provide direct and contextual information related to customer issues.
NEW QUESTION # 28
A company has a typical RAG-enabled, customer-facing chatbot on its website.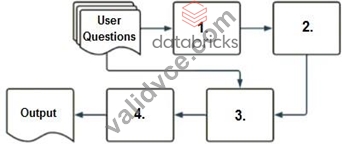
Select the correct sequence of components a user's questions will go through before the final output is returned. Use the diagram above for reference.
- A. 1.response-generating LLM, 2.vector search, 3.context-augmented prompt, 4.embedding model
- B. 1.response-generating LLM, 2.context-augmented prompt, 3.vector search, 4.embedding model
- C. 1.embedding model, 2.vector search, 3.context-augmented prompt, 4.response-generating LLM
- D. 1.context-augmented prompt, 2.vector search, 3.embedding model, 4.response-generating LLM
Answer: C
Explanation:
To understand how a typical RAG-enabled customer-facing chatbot processes a user's question, let's go through the correct sequence as depicted in the diagram and explained in option A:
Embedding Model (1):
The first step involves the user's question being processed through an embedding model. This model converts the text into a vector format that numerically represents the text. This step is essential for allowing the subsequent vector search to operate effectively.
Vector Search (2):
The vectors generated by the embedding model are then used in a vector search mechanism. This search identifies the most relevant documents or previously answered questions that are stored in a vector format in a database.
Context-Augmented Prompt (3):
The information retrieved from the vector search is used to create a context-augmented prompt. This step involves enhancing the basic user query with additional relevant information gathered to ensure the generated response is as accurate and informative as possible.
Response-Generating LLM (4):
Finally, the context-augmented prompt is fed into a response-generating large language model (LLM). This LLM uses the prompt to generate a coherent and contextually appropriate answer, which is then delivered as the final output to the user.
Why Other Options Are Less Suitable:
B, C, D: These options suggest incorrect sequences that do not align with how a RAG system typically processes queries. They misplace the role of embedding models, vector search, and response generation in an order that would not facilitate effective information retrieval and response generation.
Thus, the correct sequence is embedding model, vector search, context-augmented prompt, response-generating LLM, which is option A.
NEW QUESTION # 29
A Generative AI Engineer is tasked with deploying an application that takes advantage of a custom MLflow Pyfunc model to return some interim results.
How should they configure the endpoint to pass the secrets and credentials?
- A. Add credentials using environment variables
- B. Pass the secrets in plain text
- C. Use spark.conf.set ()
- D. Pass variables using the Databricks Feature Store API
Answer: A
Explanation:
Context: Deploying an application that uses an MLflow Pyfunc model involves managing sensitive information such as secrets and credentials securely.
Explanation of Options:
* Option A: Use spark.conf.set(): While this method can pass configurations within Spark jobs, using it for secrets is not recommended because it may expose them in logs or Spark UI.
* Option B: Pass variables using the Databricks Feature Store API: The Feature Store API is designed for managing features for machine learning, not for handling secrets or credentials.
* Option C: Add credentials using environment variables: This is a common practice for managing credentials in a secure manner, as environment variables can be accessed securely by applications without exposing them in the codebase.
* Option D: Pass the secrets in plain text: This is highly insecure and not recommended, as it exposes sensitive information directly in the code.
Therefore,Option Cis the best method for securely passing secrets and credentials to an application, protecting them from exposure.
NEW QUESTION # 30
A Generative AI Engineer has a provisioned throughput model serving endpoint as part of a RAG application and would like to monitor the serving endpoint's incoming requests and outgoing responses. The current approach is to include a micro-service in between the endpoint and the user interface to write logs to a remote server.
Which Databricks feature should they use instead which will perform the same task?
- A. DBSQL
- B. Inference Tables
- C. Lakeview
- D. Vector Search
Answer: B
Explanation:
* Problem Context: The goal is to monitor the serving endpoint for incoming requests and outgoing responses in a provisioned throughput model serving endpoint within a Retrieval-Augmented Generation (RAG) application. The current approach involves using a microservice to log requests and responses to a remote server, but the Generative AI Engineer is looking for a more streamlined solution within Databricks.
* Explanation of Options:
Option A: Vector Search: This feature is used to perform similarity searches within vector databases. It doesn't provide functionality for logging or monitoring requests and responses in a serving endpoint, so it's not applicable here.
Option B: Lakeview: Lakeview is not a feature relevant to monitoring or logging request-response cycles for serving endpoints. It might be more related to viewing data in Databricks Lakehouse but doesn't fulfill the specific monitoring requirement.
Option C: DBSQL: Databricks SQL (DBSQL) is used for running SQL queries on data stored in Databricks, primarily for analytics purposes. It doesn't provide the direct functionality needed to monitor requests and responses in real-time for an inference endpoint.
Option D: Inference Tables: This is the correct answer. Inference Tables in Databricks are designed to store the results and metadata of inference runs. This allows the system to log incoming requests and outgoing responses directly within Databricks, making it an ideal choice for monitoring the behavior of a provisioned serving endpoint. Inference Tables can be queried and analyzed, enabling easier monitoring and debugging compared to a custom microservice.
Thus, Inference Tables are the optimal feature for monitoring request and response logs within the Databricks infrastructure for a model serving endpoint.
NEW QUESTION # 31
A Generative Al Engineer is building an LLM-based application that has an important transcription (speech-to-text) task. Speed is essential for the success of the application Which open Generative Al models should be used?
- A. whisper-large-v3 (1.6B)
- B. L!ama-2-70b-chat-hf
- C. DBRX
- D. MPT-30B-lnstruct
Answer: A
Explanation:
The task requires an open generative AI model for a transcription (speech-to-text) task where speed is essential. Let's assess the options based on their suitability for transcription and performance characteristics, referencing Databricks' approach to model selection.
Option A: Llama-2-70b-chat-hf
Llama-2 is a text-based LLM optimized for chat and text generation, not speech-to-text. It lacks transcription capabilities.
Databricks Reference: "Llama models are designed for natural language generation, not audio processing" ("Databricks Model Catalog").
Option B: MPT-30B-Instruct
MPT-30B is another text-based LLM focused on instruction-following and text generation, not transcription. It's irrelevant for speech-to-text tasks.
Databricks Reference: No specific mention, but MPT is categorized under text LLMs in Databricks' ecosystem, not audio models.
Option C: DBRX
DBRX, developed by Databricks, is a powerful text-based LLM for general-purpose generation. It doesn't natively support speech-to-text and isn't optimized for transcription.
Databricks Reference: "DBRX excels at text generation and reasoning tasks" ("Introducing DBRX," 2023)-no mention of audio capabilities.
Option D: whisper-large-v3 (1.6B)
Whisper, developed by OpenAI, is an open-source model specifically designed for speech-to-text transcription. The "large-v3" variant (1.6 billion parameters) balances accuracy and efficiency, with optimizations for speed via quantization or deployment on GPUs-key for the application's requirements.
Databricks Reference: "For audio transcription, models like Whisper are recommended for their speed and accuracy" ("Generative AI Cookbook," 2023). Databricks supports Whisper integration in its MLflow or Lakehouse workflows.
Conclusion: Only D. whisper-large-v3 is a speech-to-text model, making it the sole suitable choice. Its design prioritizes transcription, and its efficiency (e.g., via optimized inference) meets the speed requirement, aligning with Databricks' model deployment best practices.
NEW QUESTION # 32
A Generative AI Engineer is designing a RAG application for answering user questions on technical regulations as they learn a new sport.
What are the steps needed to build this RAG application and deploy it?
- A. User submits queries against an LLM -> Ingest documents from a source -> Index the documents and save to Vector Search -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
- B. Ingest documents from a source -> Index the documents and saves to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> Evaluate model -> LLM generates a response -> Deploy it using Model Serving
- C. Ingest documents from a source -> Index the documents and save to Vector Search -> User submits queries against an LLM -> LLM retrieves relevant documents -> LLM generates a response -> Evaluate model -> Deploy it using Model Serving
- D. Ingest documents from a source -> Index the documents and save to Vector Search -> Evaluate model -
> Deploy it using Model Serving
Answer: C
Explanation:
The Generative AI Engineer needs to follow a methodical pipeline to build and deploy a Retrieval- Augmented Generation (RAG) application. The steps outlined in optionBaccurately reflect this process:
* Ingest documents from a source: This is the first step, where the engineer collects documents (e.g., technical regulations) that will be used for retrieval when the application answers user questions.
* Index the documents and save to Vector Search: Once the documents are ingested, they need to be embedded using a technique like embeddings (e.g., with a pre-trained model like BERT) and stored in a vector database (such as Pinecone or FAISS). This enables fast retrieval based on user queries.
* User submits queries against an LLM: Users interact with the application by submitting their queries.
These queries will be passed to the LLM.
* LLM retrieves relevant documents: The LLM works with the vector store to retrieve the most relevant documents based on their vector representations.
* LLM generates a response: Using the retrieved documents, the LLM generates a response that is tailored to the user's question.
* Evaluate model: After generating responses, the system must be evaluated to ensure the retrieved documents are relevant and the generated response is accurate. Metrics such as accuracy, relevance, and user satisfaction can be used for evaluation.
* Deploy it using Model Serving: Once the RAG pipeline is ready and evaluated, it is deployed using a model-serving platform such as Databricks Model Serving. This enables real-time inference and response generation for users.
By following these steps, the Generative AI Engineer ensures that the RAG application is both efficient and effective for the task of answering technical regulation questions.
NEW QUESTION # 33
A Generative AI Engineer is creating an LLM-powered application that will need access to up-to-date news articles and stock prices.
The design requires the use of stock prices which are stored in Delta tables and finding the latest relevant news articles by searching the internet.
How should the Generative AI Engineer architect their LLM system?
- A. Query the Delta table for volatile stock prices and use an LLM to generate a search query to investigate potential causes of the stock volatility.
- B. Use an LLM to summarize the latest news articles and lookup stock tickers from the summaries to find stock prices.
- C. Download and store news articles and stock price information in a vector store. Use a RAG architecture to retrieve and generate at runtime.
- D. Create an agent with tools for SQL querying of Delta tables and web searching, provide retrieved values to an LLM for generation of response.
Answer: D
Explanation:
To build an LLM-powered system that accesses up-to-date news articles and stock prices, the best approach is tocreate an agentthat has access to specific tools (option D).
* Agent with SQL and Web Search Capabilities:By using an agent-based architecture, the LLM can interact with external tools. The agent can query Delta tables (for up-to-date stock prices) via SQL and perform web searches to retrieve the latest news articles. This modular approach ensures the system can access both structured (stock prices) and unstructured (news) data sources dynamically.
* Why This Approach Works:
* SQL Queries for Stock Prices: Delta tables store stock prices, which the agent can query directly for the latest data.
* Web Search for News: For news articles, the agent can generate search queries and retrieve the most relevant and recent articles, then pass them to the LLM for processing.
* Why Other Options Are Less Suitable:
* A (Summarizing News for Stock Prices): This convoluted approach would not ensure accuracy when retrieving stock prices, which are already structured and stored in Delta tables.
* B (Stock Price Volatility Queries): While this could retrieve relevant information, it doesn't address how to obtain the most up-to-date news articles.
* C (Vector Store): Storing news articles and stock prices in a vector store might not capture the real-time nature of stock data and news updates, as it relies on pre-existing data rather than dynamic querying.
Thus, using an agent with access to both SQL for querying stock prices and web search for retrieving news articles is the best approach for ensuring up-to-date and accurate responses.
NEW QUESTION # 34
A Generative Al Engineer is helping a cinema extend its website's chat bot to be able to respond to questions about specific showtimes for movies currently playing at their local theater. They already have the location of the user provided by location services to their agent, and a Delta table which is continually updated with the latest showtime information by location. They want to implement this new capability In their RAG application.
Which option will do this with the least effort and in the most performant way?
- A. Create a Feature Serving Endpoint from a FeatureSpec that references an online store synced from the Delta table. Query the Feature Serving Endpoint as part of the agent logic / tool implementation.
- B. implementation. Write the Delta table contents to a text column.then embed those texts using an embedding model and store these in the vector index Look up the information based on the embedding as part of the agent logic / tool implementation.
- C. Query the Delta table directly via a SQL query constructed from the user's input using a text-to-SQL LLM in the agent logic / tool
- D. Set up a task in Databricks Workflows to write the information in the Delta table periodically to an external database such as MySQL and query the information from there as part of the agent logic / tool implementation.
Answer: A
Explanation:
The task is to extend a cinema chatbot to provide movie showtime information using a RAG application, leveraging user location and a continuously updated Delta table, with minimal effort and high performance.
Let's evaluate the options.
* Option A: Create a Feature Serving Endpoint from a FeatureSpec that references an online store synced from the Delta table. Query the Feature Serving Endpoint as part of the agent logic / tool implementation
* Databricks Feature Serving provides low-latency access to real-time data from Delta tables via an online store. Syncing the Delta table to a Feature Serving Endpoint allows the chatbot to query showtimes efficiently, integrating seamlessly into the RAG agent'stool logic. This leverages Databricks' native infrastructure, minimizing effort and ensuring performance.
* Databricks Reference:"Feature Serving Endpoints provide real-time access to Delta table data with low latency, ideal for production systems"("Databricks Feature Engineering Guide," 2023).
* Option B: Query the Delta table directly via a SQL query constructed from the user's input using a text-to-SQL LLM in the agent logic / tool
* Using a text-to-SQL LLM to generate queries adds complexity (e.g., ensuring accurate SQL generation) and latency (LLM inference + SQL execution). While feasible, it's less performant and requires more effort than a pre-built serving solution.
* Databricks Reference:"Direct SQL queries are flexible but may introduce overhead in real-time applications"("Building LLM Applications with Databricks").
* Option C: Write the Delta table contents to a text column, then embed those texts using an embedding model and store these in the vector index. Look up the information based on the embedding as part of the agent logic / tool implementation
* Converting structured Delta table data (e.g., showtimes) into text, embedding it, and using vector search is inefficient for structured lookups. It's effort-intensive (preprocessing, embedding) and less precise than direct queries, undermining performance.
* Databricks Reference:"Vector search excels for unstructured data, not structured tabular lookups"("Databricks Vector Search Documentation").
* Option D: Set up a task in Databricks Workflows to write the information in the Delta table periodically to an external database such as MySQL and query the information from there as part of the agent logic / tool implementation
* Exporting to an external database (e.g., MySQL) adds setup effort (workflow, external DB management) and latency (periodic updates vs. real-time). It's less performant and more complex than using Databricks' native tools.
* Databricks Reference:"Avoid external systems when Delta tables provide real-time data natively"("Databricks Workflows Guide").
Conclusion: Option A minimizes effort by using Databricks Feature Serving for real-time, low-latency access to the Delta table, ensuring high performance in a production-ready RAG chatbot.
NEW QUESTION # 35
A Generative AI Engineer is testing a simple prompt template in LangChain using the code below, but is getting an error:
Python
from langchain.chains import LLMChain
from langchain_community.llms import OpenAI
from langchain_core.prompts import PromptTemplate
prompt_template = "Tell me a {adjective} joke"
prompt = PromptTemplate(input_variables=["adjective"], template=prompt_template)
# ... (Error-prone section)
Assuming the API key was properly defined, what change does the Generative AI Engineer need to make to fix their chain?
- A. (Incorrect structure)
- B. (Incorrect structure)
- C. (Incorrect structure)
- D. prompt_template = "Tell me a {adjective} joke"
prompt = PromptTemplate(input_variables=["adjective"], template=prompt_template) llm = OpenAI() llm_chain = LLMChain(prompt=prompt, llm=llm) llm_chain.generate([{"adjective": "funny"}])
Answer: D
Explanation:
The error in the original snippet usually stems from the improper instantiation of the LLMChain or the incorrect call to the .generate() method. In LangChain, an LLMChain requires two primary components: an LLM (the engine) and a Prompt (the template). Option C provides the correct syntax: first, the PromptTemplate is defined with the correct input_variables. Second, the OpenAI model is instantiated. Third, the LLMChain binds the model and the prompt together. Finally, the .generate() method expects a list of dictionaries, where each dictionary represents a set of inputs for the prompt variables. Options A, B, and D in the original image contain syntax errors such as passing the variable directly into the chain initialization or missing the dictionary list format required by the standard LangChain API for batch-like generation.
NEW QUESTION # 36
A Generative AI Engineer is building an LLM to generate article summaries in the form of a type of poem, such as a haiku, given the article content. However, the initial output from the LLM does not match the desired tone or style.
Which approach will NOT improve the LLM's response to achieve the desired response?
- A. Include few-shot examples in the prompt to the LLM
- B. Fine-tune the LLM on a dataset of desired tone and style
- C. Provide the LLM with a prompt that explicitly instructs it to generate text in the desired tone and style
- D. Use a neutralizer to normalize the tone and style of the underlying documents
Answer: D
Explanation:
The task at hand is to improve the LLM's ability to generate poem-like article summaries with the desired tone and style. Using aneutralizerto normalize the tone and style of the underlying documents (option B) will not help improve the LLM's ability to generate the desired poetic style. Here's why:
* Neutralizing Underlying Documents:A neutralizer aims to reduce or standardize the tone of input data. However, this contradicts the goal, which is to generate text with aspecific tone and style(like haikus). Neutralizing the source documents will strip away the richness of the content, making it harder for the LLM to generate creative, stylistic outputs like poems.
* Why Other Options Improve Results:
* A (Explicit Instructions in the Prompt): Directly instructing the LLM to generate text in a specific tone and style helps align the output with the desired format (e.g., haikus). This is a common and effective technique in prompt engineering.
* C (Few-shot Examples): Providing examples of the desired output format helps the LLM understand the expected tone and structure, making it easier to generate similar outputs.
* D (Fine-tuning the LLM): Fine-tuning the model on a dataset that contains examples of the desired tone and style is a powerful way to improve the model's ability to generate outputs that match the target format.
Therefore, using a neutralizer (option B) isnotan effective method for achieving the goal of generating stylized poetic summaries.
NEW QUESTION # 37
A Generative AI Engineer is developing an LLM application that users can use to generate personalized birthday poems based on their names.
Which technique would be most effective in safeguarding the application, given the potential for malicious user inputs?
- A. Increase the amount of compute that powers the LLM to process input faster
- B. Ask the LLM to remind the user that the input is malicious but continue the conversation with the user
- C. Reduce the time that the users can interact with the LLM
- D. Implement a safety filter that detects any harmful inputs and ask the LLM to respond that it is unable to assist
Answer: D
Explanation:
In this case, the Generative AI Engineer is developing an application to generate personalized birthday poems, but there's a need to safeguard against malicious user inputs. The best solution is to implement a safety filter (option A) to detect harmful or inappropriate inputs.
Safety Filter Implementation:
Safety filters are essential for screening user input and preventing inappropriate content from being processed by the LLM. These filters can scan inputs for harmful language, offensive terms, or malicious content and intervene before the prompt is passed to the LLM.
Graceful Handling of Harmful Inputs:
Once the safety filter detects harmful content, the system can provide a message to the user, such as "I'm unable to assist with this request," instead of processing or responding to malicious input. This protects the system from generating harmful content and ensures a controlled interaction environment.
Why Other Options Are Less Suitable:
B (Reduce Interaction Time): Reducing the interaction time won't prevent malicious inputs from being entered.
C (Continue the Conversation): While it's possible to acknowledge malicious input, it is not safe to continue the conversation with harmful content. This could lead to legal or reputational risks.
D (Increase Compute Power): Adding more compute doesn't address the issue of harmful content and would only speed up processing without resolving safety concerns.
Therefore, implementing a safety filter that blocks harmful inputs is the most effective technique for safeguarding the application.
NEW QUESTION # 38
A Generative Al Engineer has created a RAG application to look up answers to questions about a series of fantasy novels that are being asked on the author's web forum. The fantasy novel texts are chunked and embedded into a vector store with metadata (page number, chapter number, book title), retrieved with the user's query, and provided to an LLM for response generation. The Generative AI Engineer used their intuition to pick the chunking strategy and associated configurations but now wants to more methodically choose the best values.
Which TWO strategies should the Generative AI Engineer take to optimize their chunking strategy and parameters? (Choose two.)
- A. Choose an appropriate evaluation metric (such as recall or NDCG) and experiment with changes in the chunking strategy, such as splitting chunks by paragraphs or chapters.
Choose the strategy that gives the best performance metric. - B. Create an LLM-as-a-judge metric to evaluate how well previous questions are answered by the most appropriate chunk. Optimize the chunking parameters based upon the values of the metric.
- C. Add a classifier for user queries that predicts which book will best contain the answer. Use this to filter retrieval.
- D. Pass known questions and best answers to an LLM and instruct the LLM to provide the best token count. Use a summary statistic (mean, median, etc.) of the best token counts to choose chunk size.
- E. Change embedding models and compare performance.
Answer: A,B
Explanation:
To optimize a chunking strategy for a Retrieval-Augmented Generation (RAG) application, the Generative AI Engineer needs a structured approach to evaluating the chunking strategy, ensuring that the chosen configuration retrieves the most relevant information and leads to accurate and coherent LLM responses. Here's why C and E are the correct strategies:
Strategy C: Evaluation Metrics (Recall, NDCG)
Define an evaluation metric: Common evaluation metrics such as recall, precision, or NDCG (Normalized Discounted Cumulative Gain) measure how well the retrieved chunks match the user's query and the expected response.
Recall measures the proportion of relevant information retrieved.
NDCG is often used when you want to account for both the relevance of retrieved chunks and the ranking or order in which they are retrieved.
Experiment with chunking strategies: Adjusting chunking strategies based on text structure (e.g., splitting by paragraph, chapter, or a fixed number of tokens) allows the engineer to experiment with various ways of slicing the text. Some chunks may better align with the user's query than others.
Evaluate performance: By using recall or NDCG, the engineer can methodically test various chunking strategies to identify which one yields the highest performance. This ensures that the chunking method provides the most relevant information when embedding and retrieving data from the vector store.
Strategy E: LLM-as-a-Judge Metric
Use the LLM as an evaluator: After retrieving chunks, the LLM can be used to evaluate the quality of answers based on the chunks provided. This could be framed as a "judge" function, where the LLM compares how well a given chunk answers previous user queries.
Optimize based on the LLM's judgment: By having the LLM assess previous answers and rate their relevance and accuracy, the engineer can collect feedback on how well different chunking configurations perform in real-world scenarios.
This metric could be a qualitative judgment on how closely the retrieved information matches the user's intent.
Tune chunking parameters: Based on the LLM's judgment, the engineer can adjust the chunk size or structure to better align with the LLM's responses, optimizing retrieval for future queries.
By combining these two approaches, the engineer ensures that the chunking strategy is systematically evaluated using both quantitative (recall/NDCG) and qualitative (LLM judgment) methods. This balanced optimization process results in improved retrieval relevance and, consequently, better response generation by the LLM.
NEW QUESTION # 39
A small and cost-conscious startup in the cancer research field wants to build a RAG application using Foundation Model APIs.
Which strategy would allow the startup to build a good-quality RAG application while being cost-conscious and able to cater to customer needs?
- A. Limit the number of queries a customer can send per day
- B. Use the largest LLM possible because that gives the best performance for any general queries
- C. Limit the number of relevant documents available for the RAG application to retrieve from
- D. Pick a smaller LLM that is domain-specific
Answer: D
Explanation:
For a small, cost-conscious startup in the cancer research field, choosing a domain-specific and smaller LLM is the most effective strategy. Here's whyBis the best choice:
* Domain-specific performance: A smaller LLM that has been fine-tuned for the domain of cancer research will outperform a general-purpose LLM for specialized queries. This ensures high-quality responses without needing to rely on a large, expensive LLM.
* Cost-efficiency: Smaller models are cheaper to run, both in terms of compute resources and API usage costs. A domain-specific smaller LLM can deliver good quality responses without the need for the extensive computational power required by larger models.
* Focused knowledge: In a specialized field like cancer research, having an LLM tailored to the subject matter provides better relevance and accuracy for queries, while keeping costs low.Large, general- purpose LLMs may provide irrelevant information, leading to inefficiency and higher costs.
This approach allows the startup to balance quality, cost, and customer satisfaction effectively, making it the most suitable strategy.
NEW QUESTION # 40
A Generative Al Engineer has successfully ingested unstructured documents and chunked them by document sections. They would like to store the chunks in a Vector Search index. The current format of the dataframe has two columns: (i) original document file name (ii) an array of text chunks for each document.
What is the most performant way to store this dataframe?
- A. Split the data into train and test set, create a unique identifier for each document, then save to a Delta table
- B. Flatten the dataframe to one chunk per row, create a unique identifier for each row, and save to a Delta table
- C. Store each chunk as an independent JSON file in Unity Catalog Volume. For each JSON file, the key is the document section name and the value is the array of text chunks for that section
- D. First create a unique identifier for each document, then save to a Delta table
Answer: B
Explanation:
* Problem Context: The engineer needs an efficient way to store chunks of unstructured documents to facilitate easy retrieval and search. The current dataframe consists of document filenames and associated text chunks.
* Explanation of Options:
* Option A: Splitting into train and test sets is more relevant for model training scenarios and not directly applicable to storage for retrieval in a Vector Search index.
* Option B: Flattening the dataframe such that each row contains a single chunk with a unique identifier is the most performant for storage and retrieval. This structure aligns well with how data is indexed and queried in vector search applications, making it easier to retrieve specific chunks efficiently.
* Option C: Creating a unique identifier for each document only does not address the need to access individual chunks efficiently, which is critical in a Vector Search application.
* Option D: Storing each chunk as an independent JSON file creates unnecessary overhead and complexity in managing and querying large volumes of files.
OptionBis the most efficient and practical approach, allowing for streamlined indexing and retrieval processes in a Delta table environment, fitting the requirements of a Vector Search index.
NEW QUESTION # 41
A Generative AI Engineer is tasked with deploying an application that takes advantage of a custom MLflow Pyfunc model to return some interim results.
How should they configure the endpoint to pass the secrets and credentials?
- A. Add credentials using environment variables
- B. Pass the secrets in plain text
- C. Use spark.conf.set ()
- D. Pass variables using the Databricks Feature Store API
Answer: A
Explanation:
Context: Deploying an application that uses an MLflow Pyfunc model involves managing sensitive information such as secrets and credentials securely.
Explanation of Options:
* Option A: Use spark.conf.set(): While this method can pass configurations within Spark jobs, using it for secrets is not recommended because it may expose them in logs or Spark UI.
* Option B: Pass variables using the Databricks Feature Store API: The Feature Store API is designed for managing features for machine learning, not for handling secrets or credentials.
* Option C: Add credentials using environment variables: This is a common practice for managing credentials in a secure manner, as environment variables can be accessed securely by applications without exposing them in the codebase.
* Option D: Pass the secrets in plain text: This is highly insecure and not recommended, as it exposes sensitive information directly in the code.
Therefore,Option Cis the best method for securely passing secrets and credentials to an application, protecting them from exposure.
NEW QUESTION # 42
A Generative Al Engineer would like an LLM to generate formatted JSON from emails. This will require parsing and extracting the following information: order ID, date, and sender email. Here's a sample email:
They will need to write a prompt that will extract the relevant information in JSON format with the highest level of output accuracy.
Which prompt will do that?
- A. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in a human-readable format.
- B. You will receive customer emails and need to extract date, sender email, and order ID. You should return the date, sender email, and order ID information in JSON format.
- C. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
- D. You will receive customer emails and need to extract date, sender email, and order ID. Return the extracted information in JSON format.
Here's an example: {"date": "April 16, 2024", "sender_email": "[email protected]", "order_id": "RE987D"}
Answer: D
Explanation:
* Problem Context: The goal is to parse emails to extract certain pieces of information and output this in a structured JSON format. Clarity and specificity in the prompt design will ensure higher accuracy in the LLM's responses.
* Explanation of Options:
Option A: Provides a general guideline but lacks an example, which helps an LLM understand the exact format expected.
Option B: Includes a clear instruction and a specific example of the output format. Providing an example is crucial as it helps set the pattern and format in which the information should be structured, leading to more accurate results.
Option C: Does not specify that the output should be in JSON format, thus not meeting the requirement.
Option D: While it correctly asks for JSON format, it lacks an example that would guide the LLM on how to structure the JSON correctly.
Therefore, Option B is optimal as it not only specifies the required format but also illustrates it with an example, enhancing the likelihood of accurate extraction and formatting by the LLM.
NEW QUESTION # 43
A Generative Al Engineer is setting up a Databricks Vector Search that will lookup news articles by topic within 10 days of the date specified An example query might be "Tell me about monster truck news around January 5th 1992". They want to do this with the least amount of effort.
How can they set up their Vector Search index to support this use case?
- A. pass the query directly to the vector search index and return the best articles.
- B. Create separate indexes by topic and add a classifier model to appropriately pick the best index.
- C. Split articles by 10 day blocks and return the block closest to the query.
- D. Include metadata columns for article date and topic to support metadata filtering.
Answer: D
Explanation:
The task is to set up a Databricks Vector Search index for news articles, supporting queries like "monster truck news around January 5th, 1992," with minimal effort. The index must filter by topic and a 10-day date range. Let's evaluate the options.
Option A: Split articles by 10-day blocks and return the block closest to the query Pre-splitting articles into 10-day blocks requires significant preprocessing and index management (e.g., one index per block). It's effort-intensive and inflexible for dynamic date ranges.
Databricks Reference: "Static partitioning increases setup complexity; metadata filtering is preferred" ("Databricks Vector Search Documentation").
Option B: Include metadata columns for article date and topic to support metadata filtering Adding date and topic as metadata in the Vector Search index allows dynamic filtering (e.g., date ± 5 days, topic = "monster truck") at query time. This leverages Databricks' built-in metadata filtering, minimizing setup effort.
Databricks Reference: "Vector Search supports metadata filtering on columns like date or category for precise retrieval with minimal preprocessing" ("Vector Search Guide," 2023).
Option C: Pass the query directly to the vector search index and return the best articles Passing the full query (e.g., "Tell me about monster truck news around January 5th, 1992") to Vector Search relies solely on embeddings, ignoring structured filtering for date and topic. This risks inaccurate results without explicit range logic.
Databricks Reference: "Pure vector similarity may not handle temporal or categorical constraints effectively" ("Building LLM Applications with Databricks").
Option D: Create separate indexes by topic and add a classifier model to appropriately pick the best index Separate indexes per topic plus a classifier model adds significant complexity (index creation, model training, maintenance), far exceeding "least effort." It's overkill for this use case.
Databricks Reference: "Multiple indexes increase overhead; single-index with metadata is simpler" ("Databricks Vector Search Documentation").
Conclusion: Option B is the simplest and most effective solution, using metadata filtering in a single Vector Search index to handle date ranges and topics, aligning with Databricks' emphasis on efficient, low-effort setups.
NEW QUESTION # 44
A Generative AI Engineer wants to build an LLM-based solution to help a restaurant improve its online customer experience with bookings by automatically handling common customer inquiries. The goal of the solution is to minimize escalations to human intervention and phone calls while maintaining a personalized interaction. To design the solution, the Generative AI Engineer needs to define the input data to the LLM and the task it should perform.
Which input/output pair will support their goal?
- A. Input: Customer reviews; Output: Classify review sentiment
- B. Input: Online chat logs; Output: Cancellation options
- C. Input: Online chat logs; Output: Group the chat logs by users, followed by summarizing each user's interactions
- D. Input: Online chat logs; Output: Buttons that represent choices for booking details
Answer: D
Explanation:
Context: The goal is to improve the online customer experience in a restaurant by handling common inquiries about bookings, minimizing escalations, and maintaining personalized interactions.
Explanation of Options:
* Option A: Grouping and summarizing chat logs by user could provide insights into customer interactions but does not directly address the task of handling booking inquiries or minimizing escalations.
* Option B: Using chat logs to generate interactive buttons for booking details directly supports the goal of facilitating online bookings, minimizing the need for human intervention by providing clear, interactive options for customers to self-serve.
* Option C: Classifying sentiment of customer reviews does not directly help with booking inquiries, although it might provide valuable feedback insights.
* Option D: Providing cancellation options is helpful but narrowly focuses on one aspect of the booking process and doesn't support the broader goal of handling common inquiries about bookings.
Option Bbest supports the goal of improving online interactions by using chat logs to generate actionable items for customers, helping them complete booking tasks efficiently and reducing the need for human intervention.
NEW QUESTION # 45
A Generative AI Engineer is testing a simple prompt template in LangChain using the code below, but is getting an error.
Assuming the API key was properly defined, what change does the Generative AI Engineer need to make to fix their chain?
- A.

- B.

- C.

- D.

Answer: D
Explanation:
To fix the error in the LangChain code provided for using a simple prompt template, the correct approach is Option C. Here's a detailed breakdown of why Option C is the right choice and how it addresses the issue:
* Proper Initialization: In Option C, the LLMChain is correctly initialized with the LLM instance specified as OpenAI(), which likely represents a language model (like GPT) from OpenAI. This is crucial as it specifies which model to use for generating responses.
* Correct Use of Classes and Methods:
* The PromptTemplate is defined with the correct format, specifying that adjective is a variable within the template. This allows dynamic insertion of values into the template when generating text.
* The prompt variable is properly linked with the PromptTemplate, and the final template string is passed correctly.
* The LLMChain correctly references the prompt and the initialized OpenAI() instance, ensuring that the template and the model are properly linked for generating output.
Why Other Options Are Incorrect:
* Option A: Misuses the parameter passing in generate method by incorrectly structuring the dictionary.
* Option B: Incorrectly uses prompt.format method which does not exist in the context of LLMChain and PromptTemplate configuration, resulting in potential errors.
* Option D: Incorrect order and setup in the initialization parameters for LLMChain, which would likely lead to a failure in recognizing the correct configuration for prompt and LLM usage.
Thus, Option C is correct because it ensures that the LangChain components are correctly set up and integrated, adhering to proper syntax and logical flow required by LangChain's architecture. This setup avoids common pitfalls such as type errors or method misuses, which are evident in other options.
NEW QUESTION # 46
A Generative AI Engineer received the following business requirements for an external chatbot.
The chatbot needs to know what types of questions the user asks and routes to appropriate models to answer the questions. For example, the user might ask about upcoming event details. Another user might ask about purchasing tickets for a particular event.
What is an ideal workflow for such a chatbot?
- A. The chatbot should only look at previous event information
- B. The chatbot should only process payments
- C. There should be two different chatbots handling different types of user queries.
- D. The chatbot should be implemented as a multi-step LLM workflow. First, identify the type of question asked, then route the question to the appropriate model. If it's an upcoming event question, send the query to a text-to-SQL model. If it's about ticket purchasing, the customer should be redirected to a payment platform.
Answer: D
Explanation:
* Problem Context: The chatbot must handle various types of queries and intelligently route them to the appropriate responses or systems.
* Explanation of Options:
* Option A: Limiting the chatbot to only previous event information restricts its utility and does not meet the broader business requirements.
* Option B: Having two separate chatbots could unnecessarily complicate user interaction and increase maintenance overhead.
* Option C: Implementing a multi-step workflow where the chatbot first identifies the type of question and then routes it accordingly is the most efficient and scalable solution. This approach allows the chatbot to handle a variety of queries dynamically, improving user experience and operational efficiency.
* Option D: Focusing solely on payments would not satisfy all the specified user interaction needs, such as inquiring about event details.
Option Coffers a comprehensive workflow that maximizes the chatbot's utility and responsiveness to different user needs, aligning perfectly with the business requirements.
NEW QUESTION # 47
......
Databricks Databricks-Generative-AI-Engineer-Associate Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
New Real Databricks-Generative-AI-Engineer-Associate Exam Dumps Questions: https://www.validvce.com/Databricks-Generative-AI-Engineer-Associate-exam-collection.html
Databricks-Generative-AI-Engineer-Associate Exam Dumps - Databricks Practice Test Questions: https://drive.google.com/open?id=1oSKNCOm2GEJHr_XwZNS2KjX0iGolpuHj