![]()
Exam Questions and Answers for DP-100 Study Guide Questions and Answers!
Designing and Implementing a Data Science Solution on Azure Certification Sample Questions and Practice Exam
Microsoft DP-100 Certification Exam is a comprehensive test designed to assess the candidate's knowledge and expertise in designing and implementing data science solutions on the Azure platform. DP-100 exam is designed for data professionals, data scientists, and developers who want to expand their skill set and validate their knowledge of Azure data services. The DP-100 exam covers a wide range of topics, including data exploration and preparation, modeling, deployment, and monitoring.
Step 5: Studying with Books
Books is another efficient preparation tool. There are several guides available for the Microsoft DP-100 exam but the most popular are listed below:
- How I Passed DP-100: Designing and Implementing a Data Science Solution on Azure: Sure Shot Certification Tips by Empirical Matt Publications
- Designing and Implementing a Data Science Solution on Azure: Prepare for exam DP-100 by Stavros Koureas
- Learn How to Pass DP-100: Designing and Implementing a Data Science Solution on Azure Exam: Learn at your fingertips by Rodrezil Publications
- Exam Ref DP-100 Designing and Implementing a Data Science Solution on Azure 1st Edition by Pierstefano Tucci
- Designing and Implementing a Data Science Solution on Azure - Exam Prep: Microsoft Azure DP-100 Certification Exam | Most Unique & Latest Questionnaires by VB Dev
Microsoft DP-100 exam is an important certification for data professionals who want to demonstrate their skills in designing and implementing data science solutions on Azure. DP-100 exam validates the candidate's ability to design and implement machine learning models, process and transform data, and design and implement data science workflows. Designing and Implementing a Data Science Solution on Azure certification is highly valued in the industry and can help data professionals advance their careers and increase their earning potential.
NEW QUESTION # 202
You create a binary classification model to predict whether a person has a disease.
You need to detect possible classification errors.
Which error type should you choose for each description? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Answer:
Explanation:
Explanation:
Box 1: True Positive
A true positive is an outcome where the model correctly predicts the positive class Box 2: True Negative A true negative is an outcome where the model correctly predicts the negative class.
Box 3: False Positive
A false positive is an outcome where the model incorrectly predicts the positive class.
Box 4: False Negative
A false negative is an outcome where the model incorrectly predicts the negative class.
Note: Let's make the following definitions:
"Wolf" is a positive class.
"No wolf" is a negative class.
We can summarize our "wolf-prediction" model using a 2x2 confusion matrix that depicts all four possible outcomes:
Reference:
https://developers.google.com/machine-learning/crash-course/classification/true-false-positive-negative
NEW QUESTION # 203
You use Azure Machine Learning to train and register a model.
You must deploy the model into production as a real-time web service to an inference cluster named service-compute that the IT department has created in the Azure Machine Learning workspace.
Client applications consuming the deployed web service must be authenticated based on their Azure Active Directory service principal.
You need to write a script that uses the Azure Machine Learning SDK to deploy the model. The necessary modules have been imported.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation: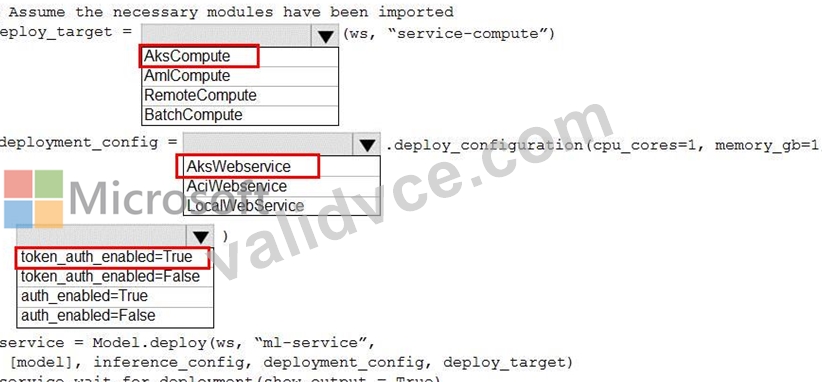
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-deploy-azure-kubernetes-service
https://docs.microsoft.com/en-us/azure/databricks/dev-tools/api/latest/aad/service-prin-aad-token
NEW QUESTION # 204
You are developing a linear regression model in Azure Machine Learning Studio. You run an experiment to compare different algorithms.
The following image displays the results dataset output:
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the image.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation:
Box 1: Boosted Decision Tree Regression
Mean absolute error (MAE) measures how close the predictions are to the actual outcomes; thus, a lower score is better.
Box 2:
Online Gradient Descent: If you want the algorithm to find the best parameters for you, set Create trainer mode option to Parameter Range. You can then specify multiple values for the algorithm to try.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
NEW QUESTION # 205
You are solving a classification task.
The dataset is imbalanced.
You need to select an Azure Machine Learning Studio module to improve the classification accuracy.
Which module should you use?
- A. Synthetic Minority Oversampling Technique (SMOTE)
- B. Filter Based Feature Selection
- C. Permutation Feature Importance
- D. Fisher Linear Discriminant Analysis
Answer: A
Explanation:
Explanation
Explanation:
Use the SMOTE module in Azure Machine Learning Studio (classic) to increase the number of underepresented cases in a dataset used for machine learning. SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
You connect the SMOTE module to a dataset that is imbalanced. There are many reasons why a dataset might be imbalanced: the category you are targeting might be very rare in the population, or the data might simply be difficult to collect. Typically, you use SMOTE when the class you want to analyze is under-represented.
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
NEW QUESTION # 206
You need to define a process for penalty event detection.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
1 - Import the global model and build the local model using PyTorch.
2 - Build the global model using PyTorch.
3 - Build the global model using TensorFlow.
4 - Import the global model and build the local model using TensorFlow.
NEW QUESTION # 207
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You have a Python script named train.py in a local folder named scripts. The script trains a regression model by using scikit-learn. The script includes code to load a training data file which is also located in the scripts folder.
You must run the script as an Azure ML experiment on a compute cluster named aml-compute.
You need to configure the run to ensure that the environment includes the required packages for model training. You have instantiated a variable named aml-compute that references the target compute cluster.
Solution: Run the following code:
Does the solution meet the goal?
- A. No
- B. Yes
Answer: B
Explanation:
Explanation
The scikit-learn estimator provides a simple way of launching a scikit-learn training job on a compute target. It is implemented through the SKLearn class, which can be used to support single-node CPU training.
Example:
from azureml.train.sklearn import SKLearn
}
estimator = SKLearn(source_directory=project_folder,
compute_target=compute_target,
entry_script='train_iris.py'
)
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-train-scikit-learn
NEW QUESTION # 208
You need to configure the Permutation Feature Importance module for the model training requirements.
What should you do? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Box 1: 500
For Random seed, type a value to use as seed for randomization. If you specify 0 (the default), a number is generated based on the system clock.
A seed value is optional, but you should provide a value if you want reproducibility across runs of the same experiment.
Here we must replicate the findings.
Box 2: Mean Absolute Error
Scenario: Given a trained model and a test dataset, you must compute the Permutation Feature Importance scores of feature variables. You need to set up the Permutation Feature Importance module to select the correct metric to investigate the model's accuracy and replicate the findings.
Regression. Choose one of the following: Precision, Recall, Mean Absolute Error , Root Mean Squared Error, Relative Absolute Error, Relative Squared Error, Coefficient of Determination References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/permutation-feature-importan
NEW QUESTION # 209
You create an experiment in Azure Machine Learning Studio- You add a training dataset that contains 10.000 rows. The first 9.000 rows represent class 0 (90 percent). The first 1.000 rows represent class 1 (10 percent).
The training set is unbalanced between two Classes. You must increase the number of training examples for class 1 to 4,000 by using data rows. You add the Synthetic Minority Oversampling Technique (SMOTE) module to the experiment.
You need to configure the module.
Which values should you use? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 210
You have an Azure Machine Learning workspace. You are running an experiment on your local computer.
You need to use MLflow Tracking to store metrics and artifacts from your local experiment runs in the workspace.
In which order should you perform the actions? To answer, move all actions from the list of actions to the answer area and arrange them in the correct order.
Answer:
Explanation:
Explanation
NEW QUESTION # 211
You manage an Azure Machine Learning workspace named workspace1.
You must register an Azure Blob storage datastore in workspace1 by using an access key. You develop Python SDK v2 code to import all modules required to register the datastore.
You need to complete the Python SDK v2 code to define the datastore.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 212
You are creating a machine learning model in Python. The provided dataset contains several numerical columns and one text column.
*Biker
*Cars
*Vans
*Boats
You are building a regression model using the scikit- learn Python package.
You need to transform the text data to be compatible with the scikit-learn Python package How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
NEW QUESTION # 213
You have a feature set containing the following numerical features: X, Y, and Z.
The Poisson correlation coefficient (r-value) of X, Y, and Z features is shown in the following image:
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/compute-linear-correlation
NEW QUESTION # 214
You run an automated machine learning experiment in an Azure Machine Learning workspace. Information about the run is listed in the table below:
You need to write a script that uses the Azure Machine Learning SDK to retrieve the best iteration of the experiment run.
Which Python code segment should you use?
- A.

- B.

- C.

- D.

- E.

Answer: B
Explanation:
The get_output method on automl_classifier returns the best run and the fitted model for the last invocation.
Overloads on get_output allow you to retrieve the best run and fitted model for any logged metric or for a particular iteration.
In [ ]:
best_run, fitted_model = local_run.get_output()
Reference:
https://notebooks.azure.com/azureml/projects/azureml-getting-started/html/how-to-use-azureml/automated- machine-learning/classification-with-deployment/auto-ml-classification-with-deployment.ipynb
NEW QUESTION # 215
You have a dataset that contains 2,000 rows. You are building a machine learning classification model by using Azure Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
Divide the data into subsets
Assign the rows into folds using a round-robin method
Allow rows in the dataset to be reused
How should you configure the module? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Use the Split data into partitions option when you want to divide the dataset into subsets of the data. This option is also useful when you want to create a custom number of folds for cross-validation, or to split rows into several groups.
Add the Partition and Sample module to your experiment in Studio (classic), and connect the dataset.
For Partition or sample mode, select Assign to Folds.
Use replacement in the partitioning: Select this option if you want the sampled row to be put back into the pool of rows for potential reuse. As a result, the same row might be assigned to several folds.
If you do not use replacement (the default option), the sampled row is not put back into the pool of rows for potential reuse. As a result, each row can be assigned to only one fold.
Randomized split: Select this option if you want rows to be randomly assigned to folds.
If you do not select this option, rows are assigned to folds using the round-robin method.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
NEW QUESTION # 216
You are developing a linear regression model in Azure Machine Learning Studio. You run an experiment to compare different algorithms.
The following image displays the results dataset output:
Use the drop-down menus to select the answer choice that answers each question based on the information presented in the image.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Box 1: Boosted Decision Tree Regression
Mean absolute error (MAE) measures how close the predictions are to the actual outcomes; thus, a lower score is better.
Box 2:
Online Gradient Descent: If you want the algorithm to find the best parameters for you, set Create trainer mode option to Parameter Range. You can then specify multiple values for the algorithm to try.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/evaluate-model
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/linear-regression
NEW QUESTION # 217
You need to use the Python language to build a sampling strategy for the global penalty detection models.
How should you complete the code segment? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
Explanation:
Explanation
Box 1: import pytorch as deeplearninglib
Box 2: ..DistributedSampler(Sampler)..
DistributedSampler(Sampler):
Sampler that restricts data loading to a subset of the dataset.
It is especially useful in conjunction with class:`torch.nn.parallel.DistributedDataParallel`. In such case, each process can pass a DistributedSampler instance as a DataLoader sampler, and load a subset of the original dataset that is exclusive to it.
Scenario: Sampling must guarantee mutual and collective exclusively between local and global segmentation models that share the same features.
Box 3: optimizer = deeplearninglib.train. GradientDescentOptimizer(learning_rate=0.10)
NEW QUESTION # 218
You need to implement a model development strategy to determine a user's tendency to respond to an ad.
Which technique should you use?
- A. Use a Split Rows module to partition the data based on distance travelled to the event.
- B. Use a Relative Expression Split module to partition the data based on centroid distance.
- C. Use a Split Rows module to partition the data based on centroid distance.
- D. Use a Relative Expression Split module to partition the data based on distance travelled to the event.
Answer: B
Explanation:
Explanation
Split Data partitions the rows of a dataset into two distinct sets.
The Relative Expression Split option in the Split Data module of Azure Machine Learning Studio is helpful when you need to divide a dataset into training and testing datasets using a numerical expression.
Relative Expression Split: Use this option whenever you want to apply a condition to a number column. The number could be a date/time field, a column containing age or dollar amounts, or even a percentage. For example, you might want to divide your data set depending on the cost of the items, group people by age ranges, or separate data by a calendar date.
Scenario:
Local market segmentation models will be applied before determining a user's propensity to respond to an advertisement.
The distribution of features across training and production data are not consistent References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/split-data
Topic 1, Case Study 1
Overview
You are a data scientist in a company that provides data science for professional sporting events. Models will be global and local market data to meet the following business goals:
*Understand sentiment of mobile device users at sporting events based on audio from crowd reactions.
*Access a user's tendency to respond to an advertisement.
*Customize styles of ads served on mobile devices.
*Use video to detect penalty events.
Current environment
Requirements
* Media used for penalty event detection will be provided by consumer devices. Media may include images and videos captured during the sporting event and snared using social media. The images and videos will have varying sizes and formats.
* The data available for model building comprises of seven years of sporting event media. The sporting event media includes: recorded videos, transcripts of radio commentary, and logs from related social media feeds feeds captured during the sporting events.
*Crowd sentiment will include audio recordings submitted by event attendees in both mono and stereo Formats.
Advertisements
* Ad response models must be trained at the beginning of each event and applied during the sporting event.
* Market segmentation nxxlels must optimize for similar ad resporr.r history.
* Sampling must guarantee mutual and collective exclusivity local and global segmentation models that share the same features.
* Local market segmentation models will be applied before determining a user's propensity to respond to an advertisement.
* Data scientists must be able to detect model degradation and decay.
* Ad response models must support non linear boundaries features.
* The ad propensity model uses a cut threshold is 0.45 and retrains occur if weighted Kappa deviates from 0.1
+/-5%.
* The ad propensity model uses cost factors shown in the following diagram:
The ad propensity model uses proposed cost factors shown in the following diagram:
Performance curves of current and proposed cost factor scenarios are shown in the following diagram:
Penalty detection and sentiment
Findings
*Data scientists must build an intelligent solution by using multiple machine learning models for penalty event detection.
*Data scientists must build notebooks in a local environment using automatic feature engineering and model building in machine learning pipelines.
*Notebooks must be deployed to retrain by using Spark instances with dynamic worker allocation
*Notebooks must execute with the same code on new Spark instances to recode only the source of the data.
*Global penalty detection models must be trained by using dynamic runtime graph computation during training.
*Local penalty detection models must be written by using BrainScript.
* Experiments for local crowd sentiment models must combine local penalty detection data.
* Crowd sentiment models must identify known sounds such as cheers and known catch phrases. Individual crowd sentiment models will detect similar sounds.
* All shared features for local models are continuous variables.
* Shared features must use double precision. Subsequent layers must have aggregate running mean and standard deviation metrics Available.
segments
During the initial weeks in production, the following was observed:
*Ad response rates declined.
*Drops were not consistent across ad styles.
*The distribution of features across training and production data are not consistent.
Analysis shows that of the 100 numeric features on user location and behavior, the 47 features that come from location sources are being used as raw features. A suggested experiment to remedy the bias and variance issue is to engineer 10 linearly uncorrected features.
Penalty detection and sentiment
*Initial data discovery shows a wide range of densities of target states in training data used for crowd sentiment models.
*All penalty detection models show inference phases using a Stochastic Gradient Descent (SGD) are running too stow.
*Audio samples show that the length of a catch phrase varies between 25%-47%, depending on region.
*The performance of the global penalty detection models show lower variance but higher bias when comparing training and validation sets. Before implementing any feature changes, you must confirm the bias and variance using all training and validation cases.
NEW QUESTION # 219
......
DP-100 certification dumps - Microsoft Azure DP-100 guides - 100% valid: https://www.validvce.com/DP-100-exam-collection.html
100% Pass Your DP-100 at First Attempt with ValidVCE: https://drive.google.com/open?id=1rUKvdXMb9mPREnwv2IV3Bmo-2ItyvmwS